
In this article, we will discuss the difference between data acquisition and data exploration in an AI project cycle.
Artificial intelligence (AI) is a branch of computer science that can build intelligent machines that can mimic human behaviour. It can replicate human thoughts and actions by analyzing data and surroundings, solving problems, and learning different tasks. AI-based applications are increasing exponentially in every industry, and therefore, careers in AI are also growing significantly. If you are fascinated by AI and its applications and want to pursue a career in it, then you can start your journey with AI certification. If you are already in this domain and want to do specialized training, you can go with this Artificial Intelligence and Machine Learning online course from the Great Learning.
Artificial intelligence is everywhere, and we are using it on a daily basis. Whether we are using Siri on our phone or Amazon’s Alexa, they use AI to answer your questions. Netflix and Facebook show you content based on your viewing preferences. Overall, AI has changed our lives significantly and created a lot of new opportunities.
Here, we will discuss the life cycle of an AI project and explore the difference between data acquisition and data exploration.
What is the Life Cycle of an AI Project?
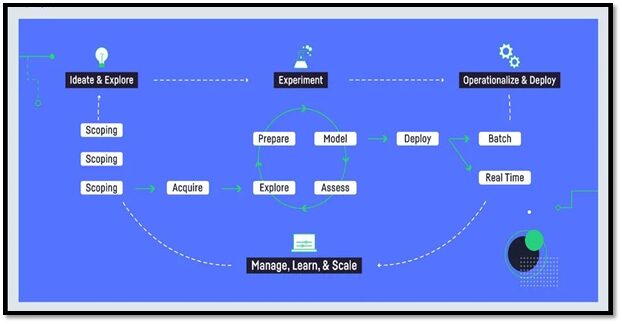
The AI project life cycle defines each and every step to derive the business value by using AI. Every AI project lifecycle consists of three main stages – project scoping, design phase, and deployment phase.
The first phase of the AI project is the project scoping and selecting the relevant use cases that the AI model will be built to address. In this stage, it is important to define the strategic business objectives and desired outcome accurately.
The second step is building the AI model. Once the project details are selected and scoped, the next step is the design or build phase. This phase can take a few days to multiple months, depending on the nature of the project.
The third stage is deploying the model into production. In this stage, ROI is a prime consideration to estimate whether the project is worthwhile or not.
Data acquisition and data exploration are the two crucial parts of the life cycle of an AI project. Let’s discuss them one by one.
Data Acquisition in AI Project Cycle
In an AI project lifecycle, data acquisition is understood as gathering, filtering, and cleaning data before the data is stored in a data storage system. Data acquisition is generally governed by four Vs – volume, velocity, variety, and value. In most cases, we assume high-value, high-velocity, high-variety, but low-value data, which makes it critical to have adaptable and time-efficient gathering, filtering, and cleaning algorithms. It ensures only high-value fragments of the data are actually processed by the data processing system.
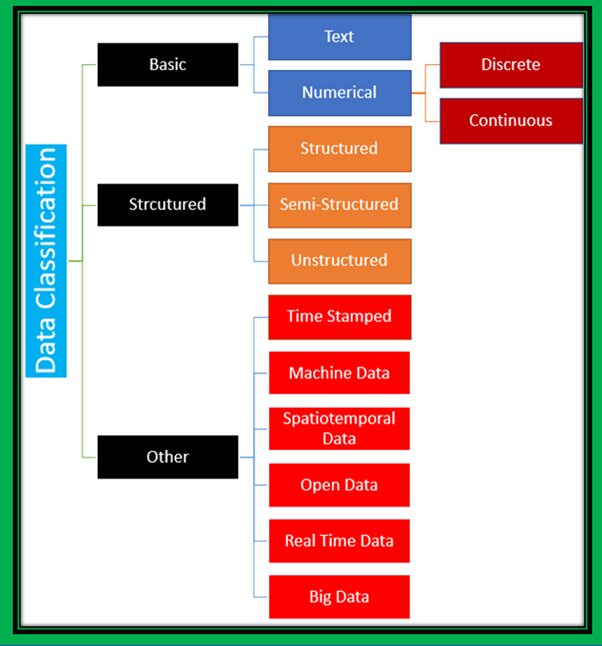
The data which we acquire can be of any type. So, it is very important to know the data classification, i.e., what kind of data we are acquiring.
Type of Data in Data Acquisition
Basically, we can classify data into two categories – numeric data and text data. Numeric data is mainly used for computation and can be further classified into discrete data and continuous data. Discrete data only contains integer numeric data, and it doesn’t have any decimal or fractional value. Continuous data represents data with any range. It can have decimal or fractional values.
Text data is mainly used to represent names, collections of words together, phrases, textual information, etc.
Data can also be classified based on structure – structured, semi-structured, and unstructured data.
Structured data has a specific pattern or set of rules, and it can be stored in specific forms such as the tabular form. Examples of structured data types are cricket scoreboard, time-table, mark sheet, etc.
Unstructured data does not have a pre-defined format, and the data is text-heavy but may contain data such as dates, numbers, and facts.
Semi-structured data does not contain a data model but has some structure. However, this type of data lacks a fixed or rigid schema.
Data Exploration in AI Project Cycle
Data exploration is the process of analysing a data set to get initial patterns, characteristics, and points of interest. It is the first step of data analysis, after data acquisition, to explore and visualize data to uncover insights from the raw data. Data exploration is generally done by using a combination of automated tools and techniques.
Business intelligence software helps in the data exploration process. This software ensures that the users are bringing quality real-time data into their analytics. With the help of real-time data, these software blend different data sources, which allow a wide range of users to perform analyses and gain insights that were previously difficult to acquire.
Now we have a clear picture of data acquisition and data exploration in an AI project cycle. Data acquisition is the process of gathering and filtering the data from various sources, while data exploration is analysing and visualizing the patterns and hidden insights from the data. These two stages are the foundations of an AI project lifecycle.
According to Jelvix, there is no best or worst type of data since it depends on needs and priorities. Before choosing the suitable data format, it is important to research the demands and consider all solutions’ advantages and disadvantages. For example, structured data lacks flexibility, and unstructured data is hard to analyze.
Final Thoughts
In this article, we have discussed data acquisition and data exploration in an AI project cycle. We have also discussed the difference between these two stages of an AI project cycle.
In the data acquisition process, we collect and clean the data, whereas, in the data exploration process, we analyse the data by using different tools. The selection of tools depends on the type of data.
Frequently Asked Questions (FAQs)
Q. What is the lifecycle of an AI project?
Ans: Generally, any AI project consists of three main stages – project scoping, designing, and model deployment. In project scoping, we select the relevant used cases for our project. Then, in the designing phase, we build or design our AI model, and in the third phase, we deploy our model.
Q. What is data acquisition in an AI project?
Ans: In an AI project, data acquisition is the process of gathering data from different sources and then cleaning it by using various tools.
Q. What is data exploration in an AI project?
Ans: Data exploration stage comes after the data acquisition stage. In this stage, we analyze and visualize the data and get some hidden insights from it.






